#Day30 #100DaysOfCode
hash table is a data structure that maps key, value pair to a table by a hash function. it is done for faster access of ele. Its efficiency depends on the hash function used.
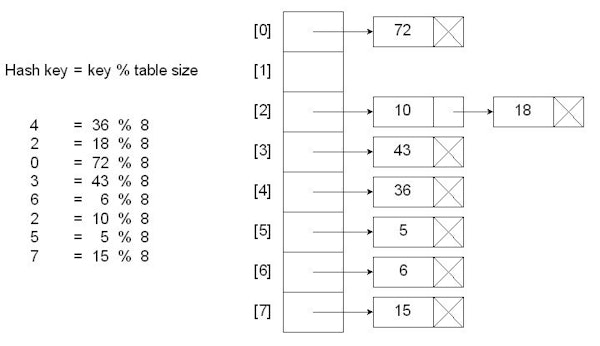
Indexing ele to table might result in similar index for different keys. This is called collision. When this happens, different techniques are used to allocate keys with same index to another index.
the first method is called chaining. as its name suggests, keys calculated by hash function having the same index will be attached to a linked list. so, the hash table is basically an array of linked list. This is just a typical implementation of chaining. Instead, it can implemented by dynamic arrays or trees.
some operations involved with hash table are insert a key to the table, delete a key, and search for a key.
the overall time complexity of chaining is O(1), comprising of insert, delete, and search. To be more specific, there is a load factor, calculated by the no of keys divided by the no of slots in the table. With this factor, time complexity of search and delete would be O(1+alpha). However, if alpha is O(1), the overall time is O(1). insert operation doesn't change as the no of keys increases.
an advantage of chaining is that an unlimited no of keys can be inserted to the table because of the linked list. therefore, chaining is suitable when there's no exact no of keys, and how frequently keys are inserted or deleted.
hash table is a data structure that maps key, value pair to a table by a hash function. it is done for faster access of ele. Its efficiency depends on the hash function used.
Indexing ele to table might result in similar index for different keys. This is called collision. When this happens, different techniques are used to allocate keys with same index to another index.
the first method is called chaining. as its name suggests, keys calculated by hash function having the same index will be attached to a linked list. so, the hash table is basically an array of linked list. This is just a typical implementation of chaining. Instead, it can implemented by dynamic arrays or trees.
some operations involved with hash table are insert a key to the table, delete a key, and search for a key.
the overall time complexity of chaining is O(1), comprising of insert, delete, and search. To be more specific, there is a load factor, calculated by the no of keys divided by the no of slots in the table. With this factor, time complexity of search and delete would be O(1+alpha). However, if alpha is O(1), the overall time is O(1). insert operation doesn't change as the no of keys increases.
an advantage of chaining is that an unlimited no of keys can be inserted to the table because of the linked list. therefore, chaining is suitable when there's no exact no of keys, and how frequently keys are inserted or deleted.